





. DOI: 10.48550/ARXIV.2410.04223")
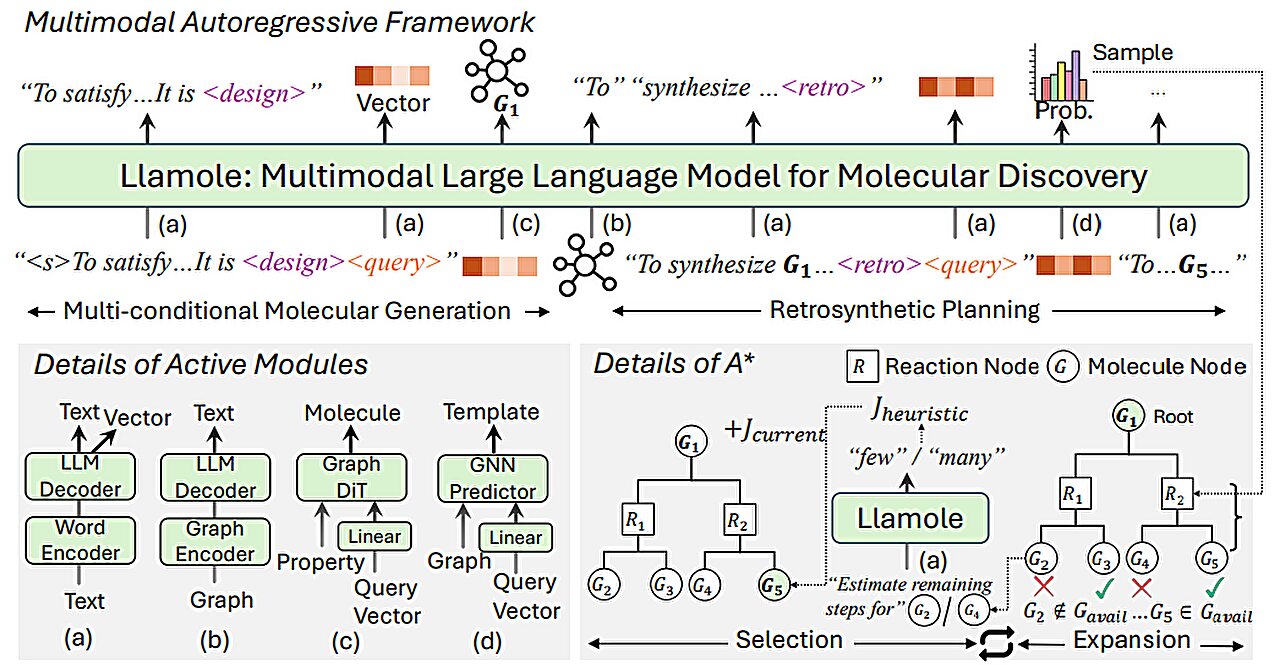
General description of Llarole. Credit: Arxiv (2024). DOI: 10.48550/ARXIV.2410.04223
The process of discovering molecules that have the necessary properties to create new medications and materials is cumbersome and expensive, consuming vast computational resources and months of human work to reduce the enormous space of possible candidates.
Large language models (LLM) such as Chatgpt could optimize this process, but allowing a llm to understand and reason about the atoms and links that form a molecule, in the same way that does so with the words that form sentences, has presented a scientific block.
MIT researchers and the MIT-IBM Watson AI laboratory created a promising approach that increases a LLM with other automatic learning models known as graphic-based models, which are specifically designed to generate and predict molecular structures.
Its method uses a LLM base to interpret the consultations of the natural language that specifies the desired molecular properties. It automatically changes between the LLM and AI base modules based on graphics to design the molecule, explain justification and generate a step -by -step plan to synthesize it. Interpae the text, the graph and the generation of synthesis steps, combining words, graphics and reactions in a common vocabulary for the LLM to consume.
Compared to existing LLM -based approaches, this multimodal technique generated molecules that better coincided user’s specifications and were more likely to have a valid synthesis plan, improving the success ratio from 5% to 35%.
It also exceeded the LLM that are more than 10 times their size and that they design synthesis molecules and routes only with text -based representations, which suggests that multimodality is key to the success of the new system.
“With luck, this could be an end -to -end solution in which, from beginning to end, we would automate the entire design and manufacture process of a molecule. If a LLM could give the answer in a few seconds, it would be a great time saving for pharmaceutical companies,” says Michael Sun, a student of the MIT graduate and co -author of a paper In this technique published in the Arxiv Preprint server.
Sun co -authors include the main author Gang Liu, a student graduated at the University of Notre Dame; Wojciech Matusik, Professor of Electrical and Informatics Engineering at MIT that leads the computer design and manufacturing group within the artificial computer and intelligence laboratory (CSAIL); Meng Jiang, associated professor at the University of Notre Dame; and the author Senior Jie Cen, scientist and senior research manager in the Laboratory of the Mit-Ibm Watson.
The research will be presented at the International Conference on Learning Representations (ICLR 2025) held in Singapore from April 24 to 28.
The best of both worlds
Large language models are not built to understand the nuances of chemistry, which is a reason why they fight with the inverse molecular design, a process of identifying molecular structures that have certain functions or properties.
LLMS turns the text into representations called Tokens, which they use to sequentially predict the following word in a sentence. But the molecules are “graphic structures”, composed of atoms and links without particular orders, which makes them difficult to encode as sequential text.
On the other hand, the powerful graphic -based models represent atoms and molecular bonds such as interconnected nodes and edges in a graph. While these models are popular for reverse molecular design, they require complex entries, they cannot understand natural language and produce results that can be difficult to interpret.
MIT researchers combined a LLM with graphic -based models in a unified framework that obtains the best of both worlds.
Islale, who represents a large model of language for molecular discovery, uses a base LLM as a guardian to understand a user’s consultation, a simple language application for a molecule with certain properties.
For example, perhaps a user looks for a molecule that can penetrate the blood brain barrier and inhibit HIV, since it has a molecular weight of 209 and certain link characteristics.
As the LLM predicts the text in response to the consultation, it changes between the graphic modules.
A module uses a graphic diffusion model to generate the molecular structure conditioned in the input requirements. A second module uses a graphic neuronal network to encode the molecular structure generated again in tokens so that the LLMs can consume. The final graphic module is a graphical reaction predictor that takes as an entrance an intermediate molecular structure and predicts a reaction step, looking for the exact set of steps to make the molecule from basic construction blocks.
The researchers created a new type of activation token that tells the LLM when to activate each module. When the LLM predicts a “design” activation token, it changes to the module that draws a molecular structure, and when it predicts a “retro” activation token, it changes to the retrosynthetic planning module that predicts the next reaction step.
“The beauty of this is that everything that the LLM generates before activating a particular module feeds on that module itself. The module is learning to operate in a way that is consistent with what it came before,” says Sun.
In the same way, the output of each module is encoded and fed again to the LLM generation process, so it includes what each module did and continue to predicting tokens based on that data.
Better and simpler molecular structures
In the end, CALOL produces an image of the molecular structure, a textual description of the molecule and a step -by -step synthesis plan that provides the details of how to do it, even the individual chemical reactions.
In the experiments involving the design of molecules that coincided with the user’s specifications, Lola exceeded 10 standard LLM, four adjusted LLMS and a specific method of last generation domain. At the same time, the success rate of retrosinthetic planning from 5% to 35% increased by generating molecules that are of higher quality, which means that they had simpler structures and lower cost construction blocks.
“On their own, the LLMs struggle to discover how to synthesize molecules because it requires great planning of several steps. Our method can generate better molecular structures that are also easier to synthesize,” says Liu.
To train and evaluate the call, the researchers built two data sets from scratch, since the existing data sets of molecular structures did not contain enough details. It increased hundreds of thousands of patented molecules with natural language descriptions generated by AI and custom description templates.
The data set that they built to adjust the LLM includes templates related to 10 molecular properties, so a limitation of flames is that it is trained to design molecules considering only those 10 numerical properties.
In future work, researchers want to generalize the call to incorporate any molecular property. In addition, they plan to improve the graphic modules to increase the successful rate of retrosisis of Láole.
And in the long run, they hope to use this approach to go beyond the molecules, creating multimodal LLMs that can handle other types of graphic -based data, such as interconnected sensors in an electricity network or transactions in a financial market.
“Lolale demonstrates the viability of using large language models such as an interface for complex data beyond the textual description, and we anticipate that they are a base that interacts with other AI algorithms to solve any graphics problem,” says Chen.
More information:
Gang Liu et al, Multimodal Large Language Models for Inverse Molecular Design with retrosinthetic planning, Arxiv (2024). DOI: 10.48550/ARXIV.2410.04223
This story is published again by mit newsy (Web.mit.edu/newsoffice/), A popular site that covers news about MIT research, innovation and teaching.
Citation: AI Method Bridges Language and Chemistry for the creation of efficient and explainable molecules (2025, April 9) Retrieved on April 17, 2025 from https://phys.org/news/2025-04-ai-method-ridges-language-chemistry.html
This document is subject to copyright. In addition to any fair treatment with the purpose of study or private research, you cannot reproduce any part without written permission. The content is provided only for information purposes.
#Pure #method #language #chemistry #creation #efficient #explainable #molecules



