PostgreSQL, MySQL y Oracle han impulsado sistemas empresariales durante décadas; optimizado para esquemas claramente definidos, integridad transaccional y rendimiento predecible. Se destacan en responder lo que preguntaste, no lo que quisiste decir.
Aquí está el problema: la IA lo cambia todo.
Los sistemas de inteligencia artificial modernos no solo buscan coincidencias exactas; buscan significado. Necesitan comprender las similitudes, el contexto y las relaciones ocultas en texto, imágenes y señales. Una base de datos relacional puede indicarle que dos registros comparten una identificación, pero no puede indicarle que dos oraciones significan lo mismo.
Por eso existen las bases de datos vectoriales. En lugar de hacer coincidir claves exactas, miden la cercanía semántica; qué tan “cercano en significado” es un dato a otro. Utilizando incrustaciones, transforman datos en un espacio numérico de alta dimensión donde la proximidad representa relevancia. Esto desbloquea capacidades como búsqueda semántica, recomendaciones personalizadas y generación aumentada de recuperación (RAG) para las que los sistemas tradicionales nunca fueron diseñados.
En este artículo, exploraremos en qué se diferencian las bases de datos vectoriales de los sistemas relacionales tradicionales, desde la arquitectura hasta el rendimiento. Aprenderá qué considerar al construir una infraestructura de datos escalable y preparada para IA que conecte precisión con comprensión.
Quizás le interese: ¿Cómo puede Cloud Computing Essentials generar beneficios para las empresas?
Bases de datos tradicionales: fortalezas y limitaciones
Bases de datos relacionales como PostgreSQL, mysql, Oráculoy auroras amazónicas están optimizados para cargas de trabajo transaccionales estructuradas. Organizan datos en tablas con esquemas definidos y se basan en SQL para consultar.
Las fortalezas clave incluyen:
- Rendimiento predecible – Cumplimiento de ACID garantiza coherencia e integridad.
- Indexación eficiente – Los índices de árbol B y hash permiten búsquedas y uniones rápidas.
- Seguridad transaccional – Ideal para sistemas financieros, ERP y cargas de trabajo de comercio electrónico.
Pero estas fortalezas tienen limitaciones cuando se manejan datos basados en IA:
- Rigidez del esquema – Las estructuras predefinidas dificultan la adaptación a entradas no estructuradas como texto, imágenes o incrustaciones.
- Sin búsqueda de similitudes – Las consultas SQL utilizan filtros de igualdad y rango, no cosenos ni distancias euclidianas.
- Compensaciones de escalabilidad – El escalado vertical (hardware más grande) alcanza límites al procesar millones de vectores de características.
Las bases de datos relacionales alcanzan sus limitaciones cuando los datos pasan de tablas estructuradas a un espacio de incrustación de alta dimensión.
Bases de datos vectoriales: diseñadas para cargas de trabajo impulsadas por IA
Bases de datos vectoriales están diseñados para gestionar incrustaciones de alta dimensión. Estas incorporaciones convierten puntos de datos como palabras, imágenes, audio y documentos en vectores numéricos que capturan significado y similitud.
A diferencia de los sistemas SQL, las bases de datos vectoriales utilizan algoritmos de vecino más cercano aproximado (ANN) como HNSW, IVF o PQ para almacenar y consultar estas incorporaciones. En lugar de buscar coincidencias exactas, evalúan la proximidad entre vectores para identificar las entradas “más similares”. Las principales implementaciones incluyen:
- pgvector – Agrega búsqueda vectorial a PostgreSQL.
- milvus – Una popular base de datos de vectores de código abierto para búsqueda de similitudes a gran escala.
- Piña – Una base de datos vectorial administrada para RAG y cargas de trabajo de personalización.
- Servicio AWS OpenSearch – Admite búsqueda híbrida con índices de vectores y de palabras clave.
- FAISS – Una biblioteca de Meta optimizada para el cálculo de similitud de vectores.

Las bases de datos vectoriales están diseñadas específicamente para casos de uso como:
- Búsqueda semántica: Recupere documentos con significado relacionado, no texto idéntico.
- Personalización: Relacione a los usuarios con productos o contenidos basándose en incorporaciones de comportamiento.
- Sistemas de recomendación: Encuentre los artículos más similares a los que les gustan a los usuarios.
- Búsqueda multimodal: Consulta a través de incrustaciones de texto, imágenes y videos juntos.
Esta arquitectura desbloquea el rendimiento que SQL no puede lograr cuando maneja datos no estructurados y ricos en significado.
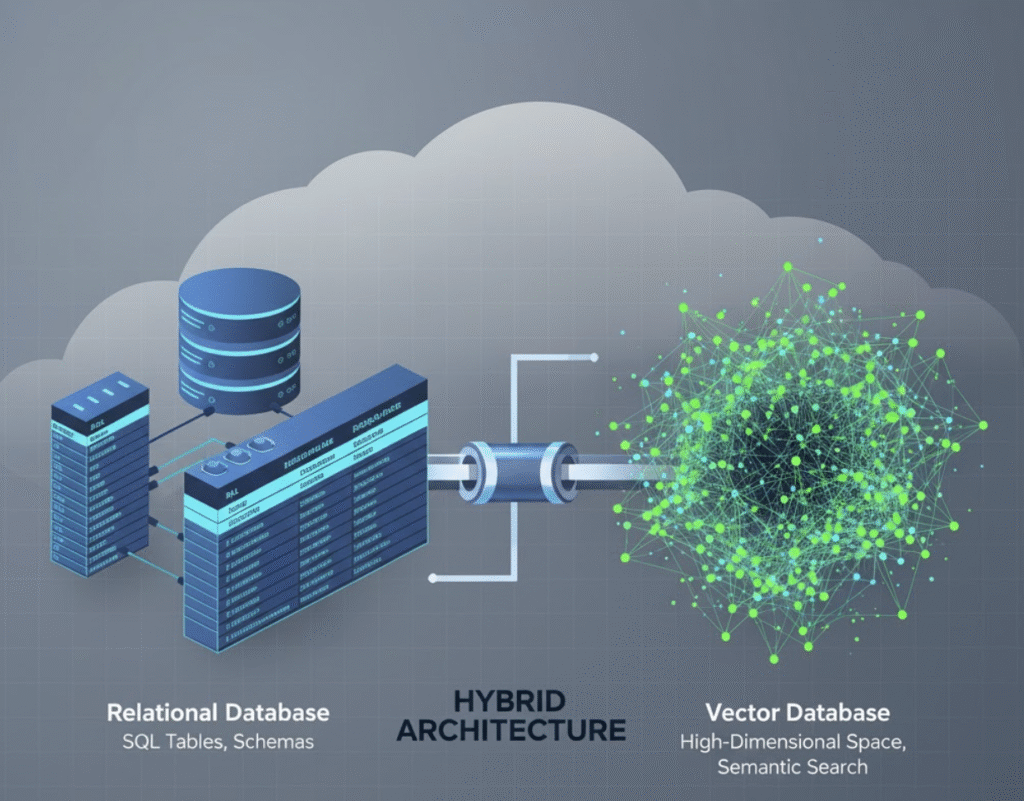
Bases de datos tradicionales versus bases de datos vectoriales: comparación arquitectónica
Las bases de datos tradicionales y vectoriales difieren tanto en cómo como en qué almacenan:
| Característica | Bases de datos tradicionales | Bases de datos vectoriales |
| Tipo de datos | Estructurado, tabular (filas, columnas) | No estructurado (incrustaciones, vectores de características) |
| Tipo de consulta | Igualdad, alcance, une. | Similitud, métricas de distancia. |
| Indexación | Árboles B, mapas hash | HNSW, FIV, PQ |
| Escala | Vertical (ampliación) | Horizontal (escalado horizontal) |
| Estado latente | Milisegundo para transacciones | Subsegundo para consultas ANN |
| Mejor uso | Transacciones, informes | Búsqueda por IA, recomendaciones, RAG |
Las bases de datos vectoriales no están diseñadas para reemplazar las capacidades de las bases de datos tradicionales, sino que las complementan. Los sistemas tradicionales todavía manejan transacciones y datos estructurados con precisión. Bases de datos vectoriales asumir una clase diferente de problema: cargas de trabajo semánticas donde el objetivo es encontrar significado, no solo hacer coincidir claves.
Leer más: Optimización del rendimiento y la escalabilidad de la computación en la nube.
Casos de uso empresarial
Muchas organizaciones ahora están implementando bases de datos vectoriales en plataformas en la nube para una mejor escalabilidad e integración con modelos de IA.
A continuación se muestran algunos casos de uso empresarial clave en los que las bases de datos vectoriales realmente brillan:
Recuperación-Generación Aumentada (RAG)
Las bases de datos vectoriales almacenan incrustaciones de documentos para LLM. Cuando un usuario solicita al sistema, este recupera documentos semánticamente relevantes y los pasa al modelo. Este enfoque ofrece respuestas precisas y conscientes del contexto sin volver a capacitar ni ajustar su modelo básico.
Personalización y recomendaciones
El comportamiento del usuario, las descripciones de productos y las interacciones se transforman en incrustaciones. La búsqueda por similitud ayuda a recomendar productos o contenido que se alinean con la actividad anterior del usuario, mucho más allá de la concordancia de palabras clave.
Detección de fraude
Las anomalías son prominentes en el espacio vectorial. Al incorporar patrones de transacciones, las bases de datos vectoriales pueden detectar desviaciones que indiquen un comportamiento fraudulento más rápidamente que los sistemas basados en reglas.
Búsqueda multimodal
Para industrias como la minorista o los medios de comunicación, las bases de datos vectoriales permiten realizar búsquedas en texto, imágenes y videos simultáneamente. Por ejemplo, al consultar “zapatillas rojas para correr” se obtienen productos visual y semánticamente similares.
Estas aplicaciones se basan en canalizaciones eficientes para transformar datos sin procesar en incrustaciones y alimentarlos en espacios vectoriales consultables.
Arquitectura de datos híbrida: lo mejor de ambos mundos
La mayoría de las empresas no reemplazan sus bases de datos relacionales, y no deberían hacerlo. En cambio, están integrando capacidades vectoriales en los sistemas existentes.
- PostgreSQL con pgvector permite a los desarrolladores agregar campos vectoriales a tablas relacionales, combinando datos estructurados con búsqueda por similitud.
- AWS OpenSearch permite consultas híbridas que combinan la relevancia de las palabras clave con la similitud de vectores.
- Milvus en el servicio AWS Elastic Kubernetes (EKS) se integra en lagos de datos más amplios para cargas de trabajo de IA escalables.
En las arquitecturas híbridas, los metadatos estructurados (por ejemplo, ID de usuario, categorías) permanecen en las bases de datos tradicionales, mientras que las incrustaciones residen en almacenes de vectores. Esta separación permite a los equipos ejecutar consultas transaccionales y basadas en IA en paralelo sin duplicar la infraestructura.
Sin embargo, esto introduce nuevos desafíos:
- Sincronización de datos – Mantener las incrustaciones alineadas con los datos de origen actualizados.
- Alineación de esquemas – Mantener identificadores consistentes entre sistemas.
- Gobernanza y cumplimiento: Controlar el acceso a incrustaciones que pueden codificar información confidencial.
Cuando se resuelve correctamente, este modelo híbrido ofrece comprensión estructural y semántica, una base para la IA a escala empresarial.
Consideraciones de implementación para bases de datos vectoriales
La implementación de bases de datos vectoriales no se trata sólo de almacenar incrustaciones; se trata de ingeniería para lograr velocidad, escala y confiabilidad. Estas prioridades de diseño ayudan a garantizar un rendimiento de nivel de producción en entornos empresariales.
Integración y manejo de consultas
La integración eficiente es clave. Por ejemplo, puede utilizar middleware o API para combinar consultas SQL y vectoriales. Marcos como LangChain, extensiones pgvectory Búsqueda híbrida OpenSearch Simplifique la conexión de metadatos estructurados con resultados de similitud basados en vectores. Este enfoque unificado mantiene el acceso a los datos consistente en todos los sistemas.
Optimización del rendimiento del índice
El rendimiento de la búsqueda de vectores depende de la estrategia de indexación adecuada. Puede elegir algoritmos como HNSW o FIV según el tamaño del conjunto de datos y la carga de consultas.
- HNSW (Hierarchical Navigable Small World) destaca en búsquedas de alta precisión y baja latencia.
- IVF (índice de archivos invertidos) funciona mejor para conjuntos de datos masivos donde la velocidad supera a la precisión.
El ajuste adecuado de los parámetros del índice garantiza que las consultas sigan respondiendo a escala.
Cumplimiento y seguridad de datos
Las incorporaciones representan información confidencial y deben protegerse como cualquier activo de datos empresarial. Aplique políticas de IAM, cifrado en reposo y en tránsito, y audite el registro a través de AWS CloudTrail. Evalúe qué requisitos de cumplimiento normativo necesita satisfacer (por ejemplo, GDPR, HIPAA, SOC2, Sarbanes Oxley). Existen controles granulares para el acceso y la protección de datos que requieren una cuidadosa consideración antes de comenzar el diseño.
Escalabilidad e infraestructura
Para cargas de trabajo a gran escala, implemente bases de datos vectoriales en plataformas administradas o en contenedores. Por ejemplo, Milvus en Amazon EKS escala horizontalmente entre clústeres, distribuyendo eficientemente tanto el almacenamiento como la computación. Esto proporciona un rendimiento constante a medida que crecen los datos y el volumen de consultas.

Cuando se implementan con estos principios, las bases de datos vectoriales escalan naturalmente con el tamaño de los datos y la complejidad del modelo, lo que admite cargas de trabajo de IA empresarial sin sacrificar la confiabilidad.
Donde la precisión de los datos se encuentra con la comprensión
Las bases de datos vectoriales no reemplazan los sistemas relacionales; los extienden. Las bases de datos relacionales potencian la precisión; Percepción de poder de bases de datos vectoriales. Juntos, forman arquitecturas de datos que pueden almacenar hechos e inferir significado.
Los sistemas relacionales aún imponen la integridad de cada transacción. Los sistemas vectoriales añaden la inteligencia para conectar patrones entre ellos. Combine la confiabilidad de SQL con la semántica de la búsqueda vectorial para crear aplicaciones que piensen, se adapten y evolucionen a medida que los datos crecen en volumen y complejidad.
El futuro no es transaccional ni semántico. Ambos funcionan en armonía para que los datos estén realmente preparados para la IA.
Radio de halo ayuda a los equipos de ingeniería a hacer realidad ese futuro. Diseñamos canalizaciones vectoriales escalables, optimizamos arquitecturas de datos y ofrecemos modelos como Amazonia nueva en sistemas de producción que se construyen correctamente desde la primera vez.
#Bases #datos #vectoriales #bases #datos #tradicionales #las #empresas #deben #saber